Pulling Back the Curtain: Development and Testing for Low-Latency DASH Support

As one of the largest providers in the world of content delivery and application performance solutions, Lumen® has prioritized support for low latency live streaming to meet the demand for sub-5 second “glass to glass” latency times. This industry standard, which refers to the delay between the actual live event and the rendering on end users’ screens, is based on the usual delay that exists within cable and satellite television feeds, and which until recently was a difficult standard for OTT streaming providers to meet using HTTP-based streaming standards such as HLS or DASH.
That’s changed in the past year or so with the acceptance of low latency standards for the HLS and MPEG-DASH protocols, which are now capable of delivering that sub-5 second ‘broadcast standard’ for live video delivered over the internet.
At Lumen, we have been working diligently to make sure that our CDN solution is capable of supporting that standard as well. Our recent work has focused on scaling our solution to meet the new standards for HLS and DASH, including stress and load testing to ensure that we can do so at scale. One of the most critical pieces of supporting low latency protocols is the enablement of Chunked Transfer Encoding (CTE), a process that provides the constant flow of video segments by pushing out bits before the complete segment is ingested.
The Lumen content delivery network had been optimized to support CTE prior to our most recent low latency development work, and has now been enhanced with a fill buffering technique (more on that later) that minimizes latency while maximizing cache efficiency to ensure seamless delivery for the LL-MPEG-DASH protocol.
The Big Sleep
The first step in our low latency project was to baseline existing performance. Time To First Byte (TTFB) is one of the key metrics that we track to ensure end-user latency is kept to a minimum, which we monitor using a sophisticated Data Analytics platform that allows us to interrogate the performance of each and every http response. Reviewing TTFB cumulative distribution for live streaming traffic, we noticed an unexpected delay around the 500 ms mark. Usually, TTFB delays like this are caused by a latency (or lay) on the customer’s origin, but in this case the latency was seen for many customers.
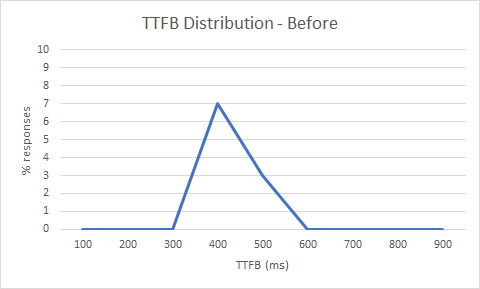
An unexpected TTFB delay of ~500ms
Source: Lumen internal monitoring
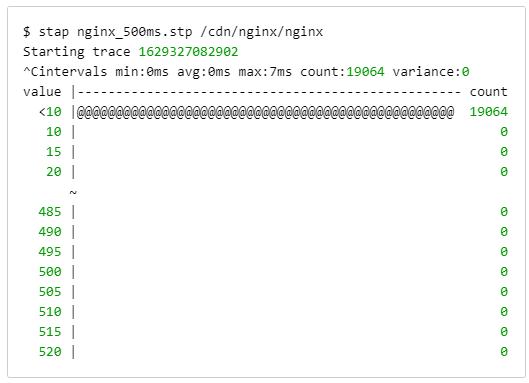
From previous experience working with Nginx’s cache locking mechanism, we were suspicious that it was causing the delays. It was time to bring out SystemTap to confirm. SystemTap is an open-source Linux tool that serves as our go-to solution for tracing performance bottlenecks. After a bit of trial and error in the lab, we were able to craft a SystemTap (.stp) script that traced the source of the mysterious 500 ms delays.

SystemTap tracing ngx_http_file_cache_lock()
The SystemTap script above traces delays in calls to ngx_http_file_cache_lock(). The time it takes to enter and exit this function is usually a few milliseconds, but we were occasionally seeing delays of up to 500 ms. Using the handy @hist_log() function, you can see the distribution of delays between entering and exiting ngx_http_file_cache_lock().
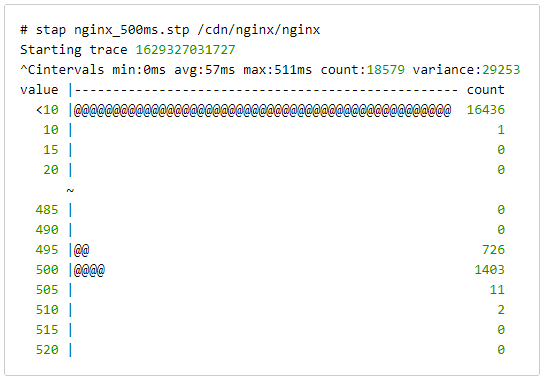
SystemTap histogram without fill buffering
Reviewing the Nginx source code, the cause of the delay became clear. Within ngx_http_file_cache_lock(), there is a section of code that can cause a client request to be put to sleep:

Nginx source code for putting a request to sleep
Summarizing the code flow, we have:
- A request arrives for content that is not in cache.
- A lock is acquired to serialize concurrent access. State on the associated ngx_http_cache_t object is updated to indicate that it needs to wait for content to fill.
- If additional clients arrive while still filling, they block waiting for the content to be fully downloaded.
- The code does not use traditional wait / notify semantics, but instead associates an event timer with the waiting clients.
- When the content is available, waiting clients are not immediately notified, but wait for their associated timers to expire.
- If a client is ‘unlucky’ their timer could expire just prior to completion of the fill, which would result in another 500 ms delay.
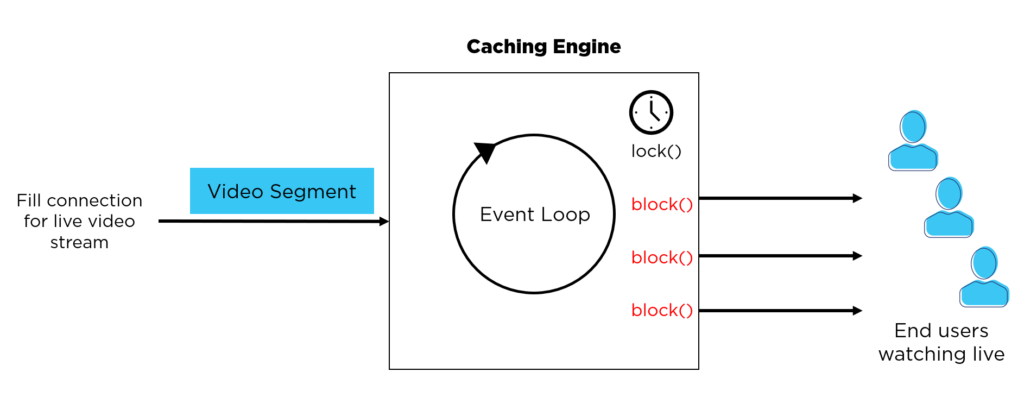
The Big Sleep
Fill Buffering
After reviewing options to eliminate the cache delay (both internally and with the great guys at Nginx) it was clear that this was not going to be an easy fix. Simply reducing the length of the 500 ms timer would not scale, as it would result in potentially thousands of clients ‘busy waiting’ for video segments to be fully downloaded into cache. Similarly, extending Nginx’s existing event notification mechanisms (see ngx_event_pipe.c) would require complicated refactoring.
In the end, we decided to leverage our in-house event library NetShell. NetShell is a library that provides all the low-level primitives needed to build scalable network applications. We were already using NetShell (in conjunction with Nginx) as part of our edge software stack, so it was natural to expand its use to address this problem.
The outline of the fix is as follows:
- Extend our NetShell component to handle fill requests to upstream caches and origins.
- Update Nginx to pass all fill requests to NetShell.
- When a fill request starts, NetShell spools the content into a separate memory fill buffer.
- If additional clients arrive while content is filling, instead of blocking the client on the event timer, we allow their connection to be fed from the data that is in the fill buffer.
- Since we avoid blocking clients waiting for the full resource to be cached, we avoid the 500 ms delay.
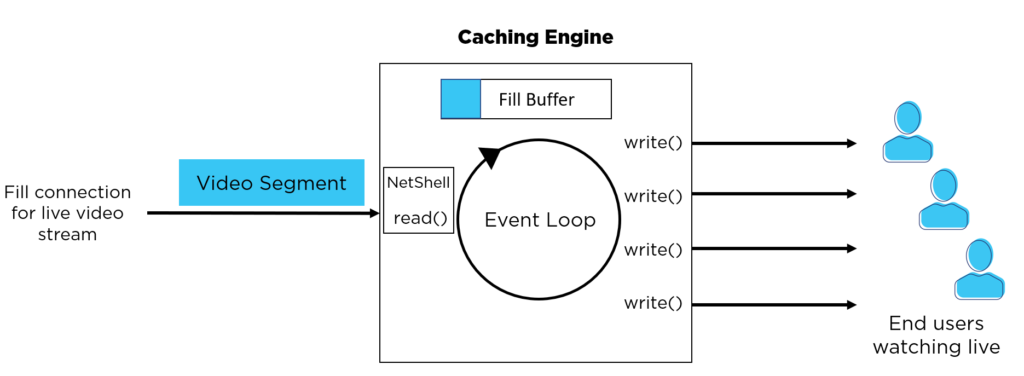
Fill Buffering
Lab Testing
Before running the new code in production, we needed to do extensive load testing in the lab.
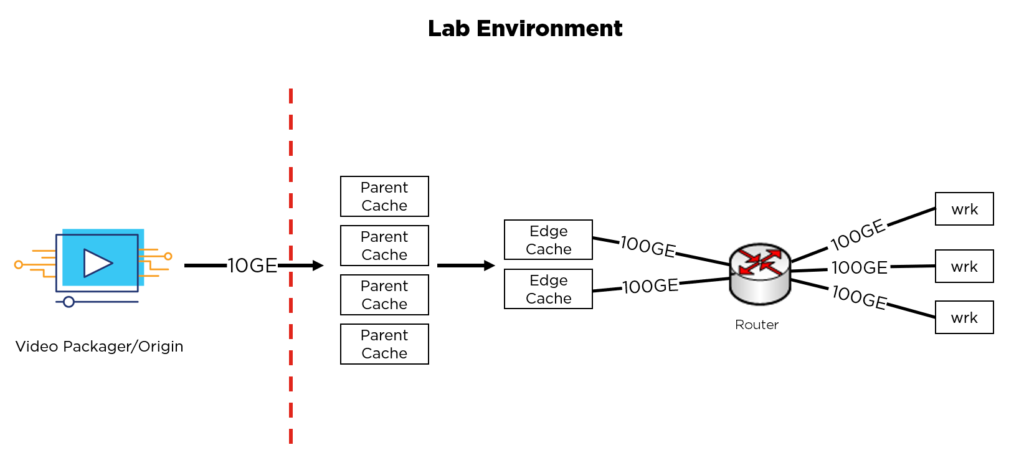
There are a number of powerful open-source tools that help with lab load testing (e.g. ApacheBench, httperf, wrk etc.). For our testing, we had some key requirements:
- The ability to simulate > 50k concurrent client connections
- The ability to drive traffic in excess of 100 Gbps
- The ability to simulate clients arriving at various offsets into a live stream
- The ability to track latency KPIs
We picked wrk. Most HTTP simulators can drive large amounts of traffic, but wrk shines because of its ability to use Lua scripting at various request processing stages. For our testing, we needed the ability to extract information about the live stream’s manifest, and then have wrk simulate thousands of clients accessing that stream at various offsets.
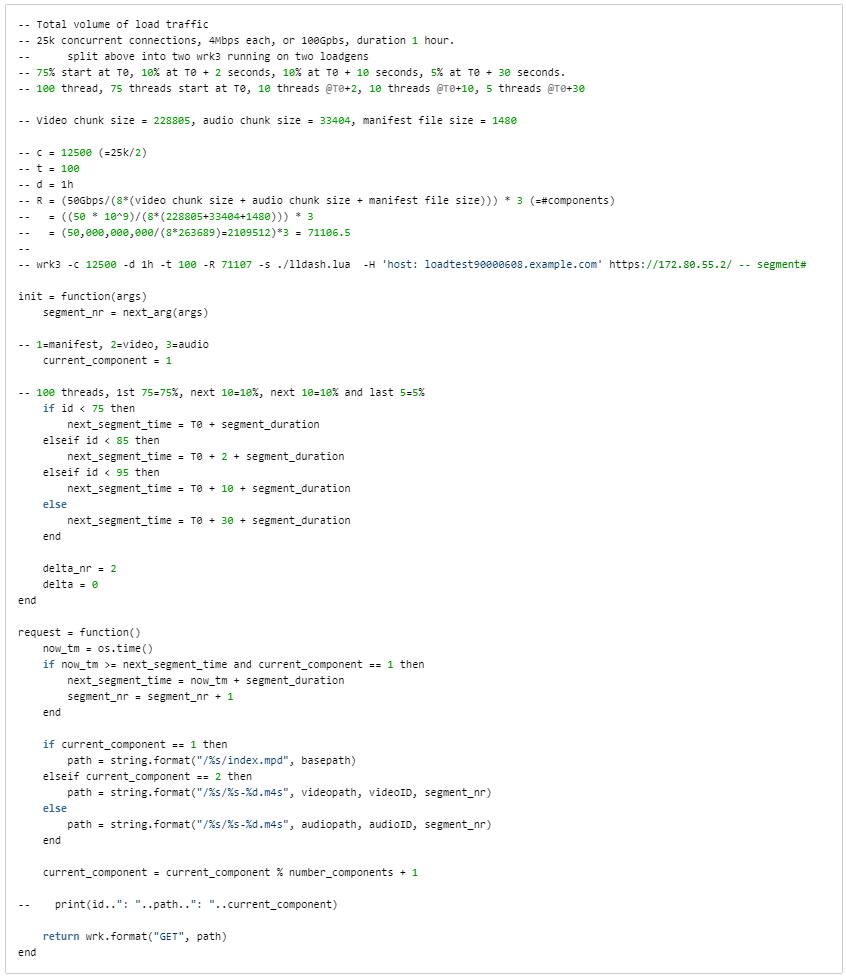
wrk Lua script
Low Latency DASH
With the fill buffer fix complete, we turned our attention to lab testing low latency DASH. In traditional live content delivery, an origin server publishes video segments as they are fully encoded. For example, if a live video stream is using a four-second segment size, the origin will publish the segment only when all four seconds of video are available. As you can imagine, quantizing the live video stream into these four-second segments introduces latency from the camera glass to client viewing.

Quantized segments
The following diagram helps visualize how waiting for full video segments adds to video delivery latency. Imagine a series of buckets that are gradually filled with water until they reach a certain level, at which point the water is poured into the next bucket and the process restarts. Waiting for full segments to be produced by the origin is similar to waiting for Bucket 1 to fill all the way to the top before allowing it to pour down to Bucket 2. Even if data (or water in the analogy) can transfer quickly from Bucket 1 to 2, it can’t make up for the latency introduced while waiting for 1 to fill up.
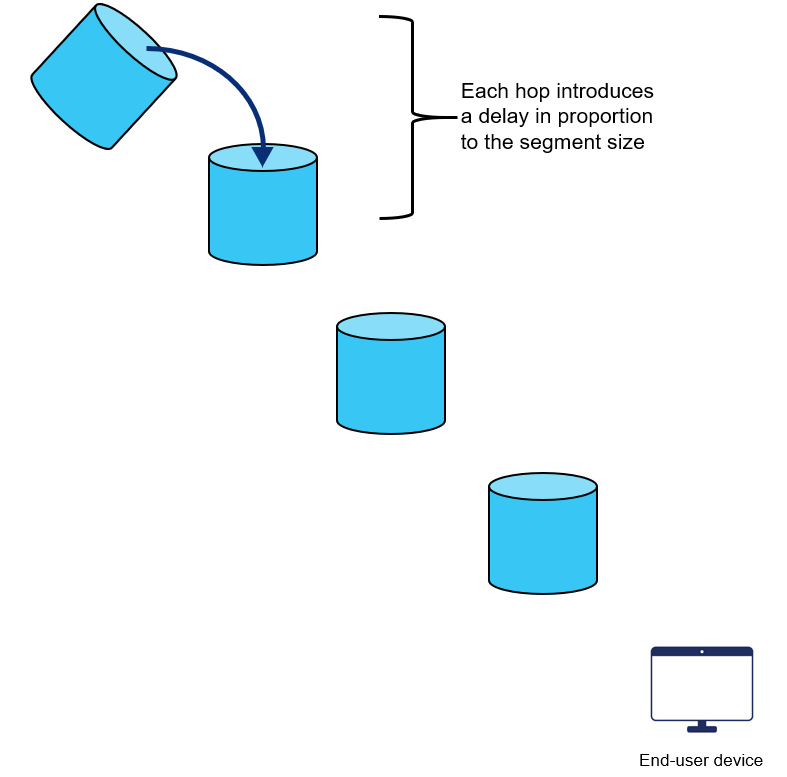
Delay waiting for full segments
To eliminate the latency associated with waiting for full segments to be published, low latency DASH takes advantage of an existing HTTP 1.1 feature called Chunked Transfer Encoding (CTE). With CTE, the Origin can signal to the CDN that it is going to send data for a video segment incrementally.
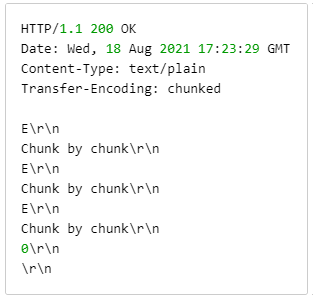
CTE response header
Going back to our original example of four-second segments, with CTE the origin is able to publish video content incrementally as it becomes available. For example, the orange chunks below represent 500 ms of content from the four-second segment. As each 500 ms chunk becomes available on the origin, it is written to the fill connection to the CDN. The CDN then repeats this process within its caching hierarchy. Instead of waiting a full four seconds to see the first video frames, the client is able to view the content as each 500 ms chunk is delivered out to their device.
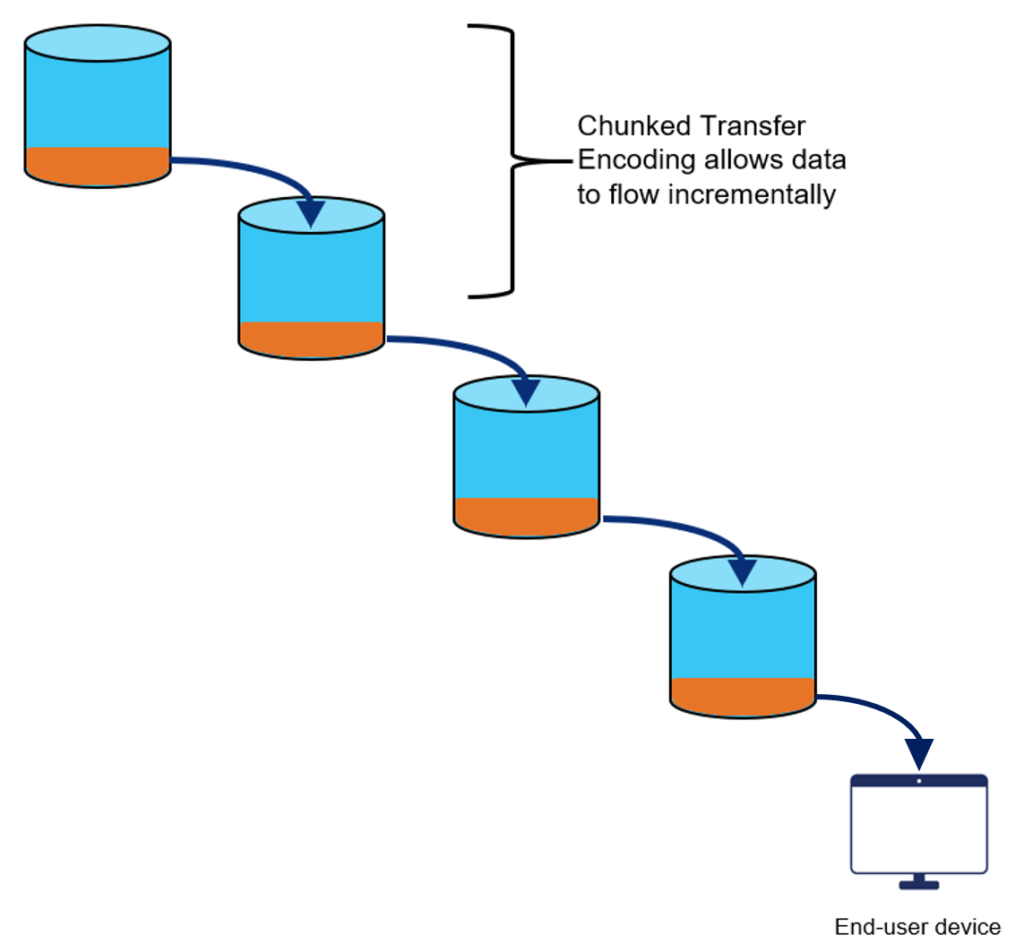
CTE sending content incrementally
Now combining CTE with the fill buffering fix discussed earlier, we get to the final view. As the Origin publishes chunks within a segment, they are quickly delivered hop-by-hop through the CDN and out to the client with minimum latency.
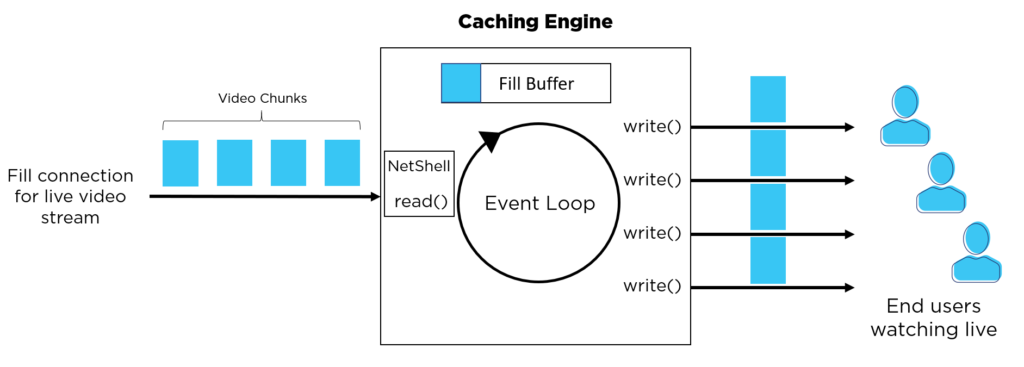
CTE response & fill buffering
Running the original SystemTap script on the new fill buffering code, we see the 500 ms delay was fixed:
SystemTap histogram with fill buffering
Conclusion
With all these changes now deployed, it was time to review the TTFB distribution in production. As the graph below shows, p50 is very smooth and consistent during the sample period. Even at p95, where we previously had the 500 ms delay, TTFB comes in under 70 ms.
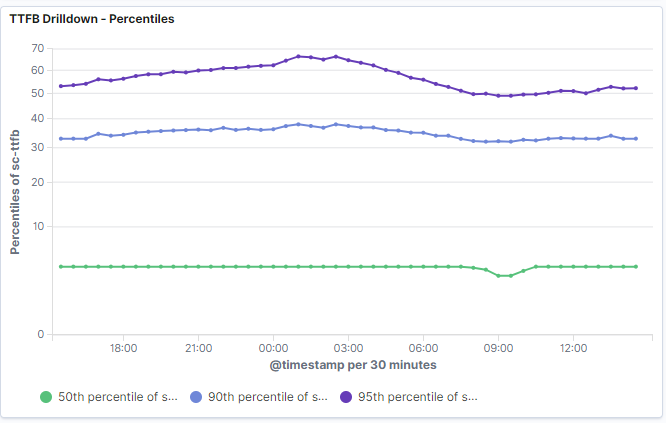
Percentile view of TTFB distribution
As anyone who works in the CDN space knows, performance optimization is never really done. Combining our data analytics pipeline with real-time code instrumentation tools like SystemTap allows for a positive feedback loop that greatly simplifies performance optimization. And although it is satisfying to see optimizations like fill buffering go from lab to production, the real focus is on the process for continuous improvement. The Lumen engineering team is looking forward to sharing additional details in future blog posts that showcase how we provide our customers and end users get the high-performing video service they’ve come to expect. Stay tuned.
This content is provided for informational purposes only and may require additional research and substantiation by the end user. In addition, the information is provided “as is” without any warranty or condition of any kind, either express or implied. Use of this information is at the end user’s own risk. Lumen does not warrant that the information will meet the end user’s requirements or that the implementation or usage of this information will result in the desired outcome of the end user. All third-party company and product or service names referenced in this article are for identification purposes only and do not imply endorsement or affiliation with Lumen. This document represents Lumen’s products and offerings as of the date of issue. Services not available everywhere. Business customers only. Lumen may change or cancel products and services or substitute similar products and services at its sole discretion without notice. ©2021 Lumen Technologies. All Rights Reserved.
Trending Now

Silence of the hops: The KadNap botnet

You may also like


